Appearance
- js 是可以通过其他容器的js引擎进行执行,现阶段最流行的引擎就是V8引擎
其他的JavaScript引擎
- SpiderMonkey:Mozilla Firefox浏览器使用的JavaScript引擎。
- Chakra:Microsoft Edge浏览器使用的JavaScript引擎。
- JavaScriptCore:Safari浏览器使用的JavaScript引擎。
- Nashorn:Java 8中的JavaScript引擎。
- Rhino:Mozilla基金会开发的JavaScript引擎,用于Java平台。
- JerryScript:专为物联网设备设计的轻量级JavaScript引擎。
- QuickJS:一个小型、快速、可嵌入的JavaScript引擎,由Fabrice Bellard开发。
- Duktape:一个小型、可嵌入的JavaScript引擎,由Duktape团队开发。
- MuJS:一个小型、可嵌入的JavaScript引擎,由Artifex Software开发。
- J2V8:一个将V8引擎嵌入Java和Android应用程序的库。
- V8是用C ++编写的Google开源高性能JavaScript引擎和WebAssembly引擎(WASM不是一种编程语言,它是一种将用一种编程语言编写的代码转换为浏览器可理解的机器代码的技术),它用于Chrome和Node.js等
- 它实现ECMAScript和WebAssembly,可以在Windows 7或更高版本,macOS 10.12+和使用x64,IA-32,ARM或MIPS处理器的Linux系统上运行
- V8可以独立运行,也可以嵌入到任何C ++应用程序。最后可以将字节码编译为CPU可以直接执行的机器码
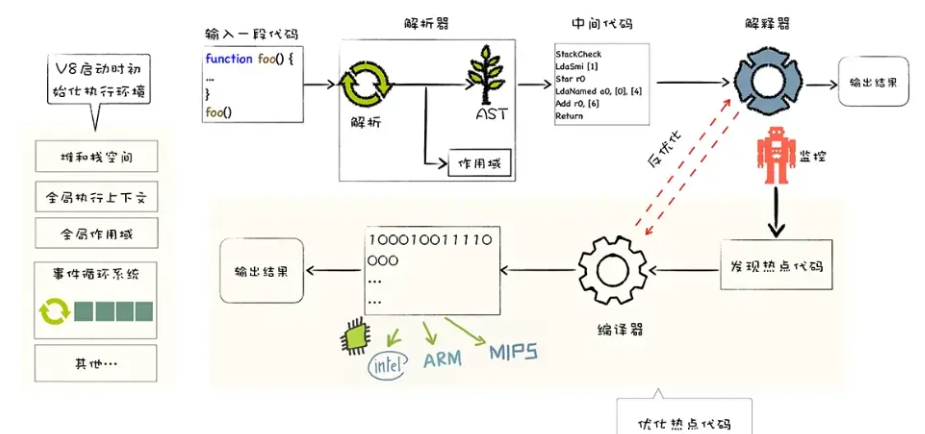
通俗理解只要将 js 引擎放到一个他能运行的环境,那么js 代码就可以运行,容器可以是浏览器 服务器 单片机 树莓派
编译器和解释器
高级语言的代码都是不能被机器直接理解,在运行前都需要将代码进行转移成机器能读懂的机器语言,这个转移的过程可以把语言划分为编译型语言和解释型语言。
| 编译型语言 | 解释型语言 |
|---|---|
| C/C++ | Python |
| Java | JavaScript |
| Go | Ruby |
| Rust | Perl |
| Swift | PHP |
| Objective-C | Lua |
| R | Shell |
| Scala | Tcl |
| Pascal | MATLAB |
编译型语言在程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件(运行前将源代码完全编译为机器码(二进制代码)的语言),这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。
在编译型语言的编译过程中,编译器首先会依次对源代码进行词法分析、语法分析,生成抽象语法树(AST),然后是优化代码,最后再生成处理器能够理解的机器码。如果编译成功,将会生成一个可执行的文件。但如果编译过程发生了语法或者其他的错误,那么编译器就会抛出异常,最后的二进制文件也不会生成成功
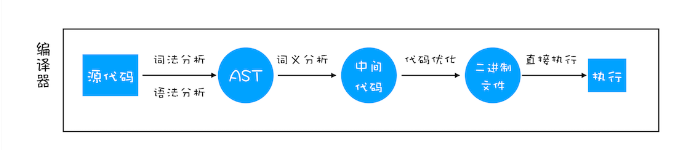
解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行
在解释型语言的解释过程中,当运行时逐行解释执行源代码的语言,同样解释器也会对源代码进行词法分析、语法分析,并生成抽象语法树(AST),不过它会再基于抽象语法树生成字节码,最后再根据字节码来执行程序、输出结果。
与编译型语言不同,解释型语言的代码不需要事先被编译为机器码或字节码,而是由解释器逐行解析并执行
js解析全流程概括
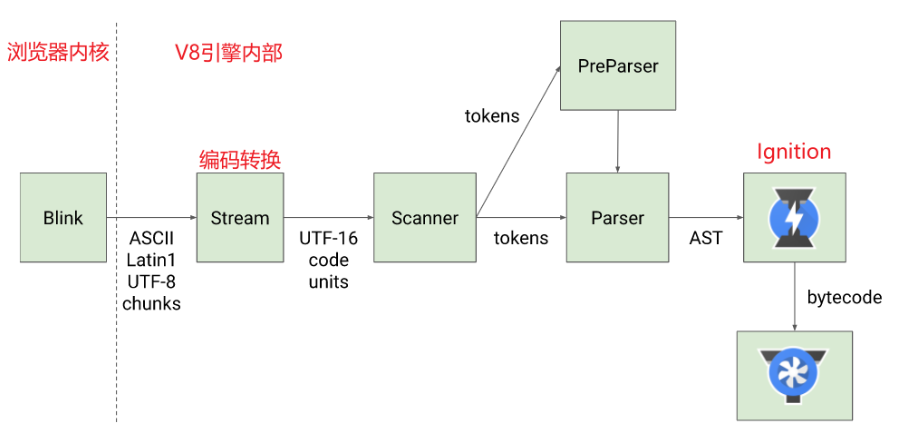
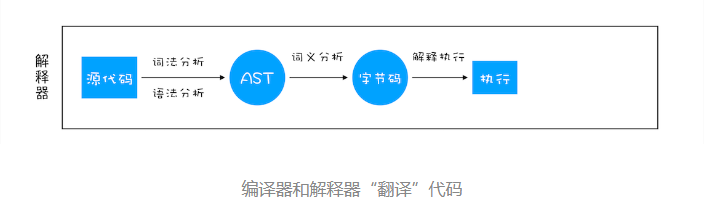
首先,浏览器的Blink内核会将JavaScript源代码交给V8引擎。V8引擎是谷歌开发的JavaScript引擎,负责处理和执行JavaScript代码。
接着,Stream(流)会获取到JavaScript源代码,并对其进行编码转换,以便后续的处理过程。
然后,Scanner(扫描器)会进行词法分析,将代码拆分成一个个有意义的词法单元,称为tokens。这就像是把一段话拆分成一个个单词。
tokens会经过语法分析,转换成AST(抽象语法树)。这个过程包括两个阶段:Parser(解析器)和PreParser(预解析器)。
- Parser:负责将tokens直接转换成AST树,这是一个结构化的表示,用于表示代码的语法结构。
- PreParser:负责预解析。这个阶段是为了提高性能。因为JavaScript代码并不是一开始就全部执行,所以V8引擎采用了Lazy Parsing(延迟解析)方案,对不必要的函数代码进行预解析。这意味着先解析急需执行的代码内容,而对函数的全量解析会在函数被调用时进行。
生成AST后,Ignition(点火器)会将AST转换成字节码,然后再转换成机器码。最后,代码进入执行过程,浏览器会根据机器码执行相应的操作。
V8 模块对应具体解析
现在最流行是V8 因此对 V8 做一个了解
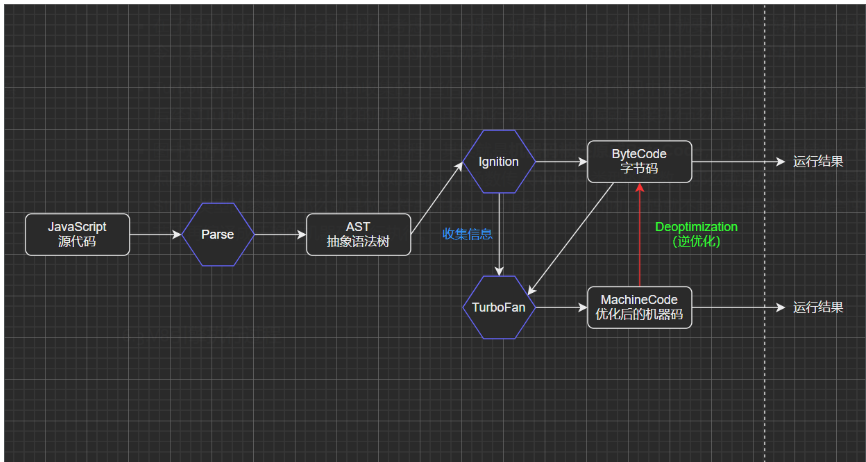
- Parse模块会将JavaScript代码转换成AST(抽象语法树),这是因为解释器并不直接认识JavaScript代码;如果函数没有被调用,那么是不会被转换成AST的;
- 参考:Parse的V8官方文档:https://v8.dev/blog/scanner
- Ignition是一个解释器,会将AST转换成ByteCode(字节码),同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);如果函数只调用一次,Ignition会解释执行ByteCode;在转换一层为字节码的好处JS运行所处的环境是不一定的,可能是windows或Linux或iOS,不同的操作系统其CPU所能识别的机器指令也是不一样的。字节码是一种中间码,本身就有跨平台的特性,然后V8引擎再根据当前所处的环境将字节码编译成对应的机器指令给当前环境的CPU执行。
- 参考: Ignition的V8官方文档:https://v8.dev/blog/ignition-interpreter
- TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能;但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;如果在编写代码时给函数传递固定类型的参数,是可以从一定程度上优化我们代码执行效率的,所以TypeScript编译出来的JavaScript代码的性能是比较好的;整个过程Ignition 在解释执行字节码的同时,收集代码信息,当它发现某一部分代码变热了之后,TurboFan 编译器便闪亮登场,把热点的字节码转换为机器码,并把转换后的机器码保存起来,以备下次使用。
对于 JavaScript 工作引擎,除了 V8 使用了“字节码 +JIT”技术之外,
- 参考: TurboFan的V8官方文档:https://v8.dev/blog/turbofan-jit
如果有一段第一次执行的字节码,解释器 Ignition 会逐条解释执行。在执行字节码的过程中,如果发现有热点代码(HotSpot),比如一段代码被重复执行多次,这种就称为热点代码,那么后台的编译器 TurboFan 就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率
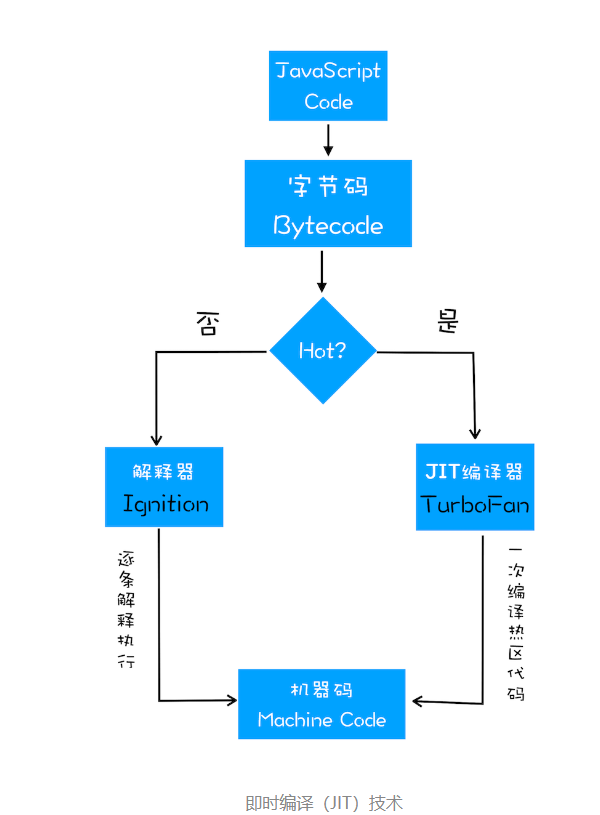
这个V8 引擎为什么需要转译,原因JavaScript是一门高级编程语言,所有的高级编程语言都是需要转换成最终的机器指令来执行的;其底层最终都是交给CPU执行,但是CPU只认识自己的指令集,也就是机器语言,而JavaScript引擎主要功能就是帮助我们将JavaScript代码翻译CPU所能认识指令,最终被CPU执行,有了引擎的转换所以js 可以一套代码做到可以在各个平台上运行
没有引擎的加持 我们需要对不同平台进行 不同的js 代码编写,让他做到在不同平台的运行
js 解析
V8 引擎为例,在 V8 引擎中 JavaScript 词法分析、生成抽象语法树、生成字节码、创建执行上下文、解释执行字节码等操作 代码的运行过程主要分成三个阶,这三个阶段会对代码进行
语法分析阶段:在这个阶段,V8 引擎会使用词法分析器(Lexer)对 JavaScript 代码进行扫描,将代码分解成一个个的词法单元(Token)。然后,通过语法分析器(Parser)将这些词法单元组合成抽象语法树(Abstract Syntax Tree,AST)。抽象语法树是一种树形结构,用于表示代码的语法结构。如果在这个过程中发现语法错误(SyntaxError)会在控制台抛出异常,V8 引擎会抛出异常并终止执行。这些和转换器 Babel、语法检查工具 ESLint、前端框架 Vue 和 React 的一些底层实现机制很类似
编译阶段:在这个阶段,V8 引擎会对抽象语法树进行处理,生成字节码(Bytecode)。字节码是一种介于源代码和机器码之间的中间代码,可以被快速解释执行。同时,V8 引擎会创建执行上下文(Execution Context),每当代码进入一个不同的运行环境时,V8 引擎都会创建一个新的执行上下文。 ,包括以下几个部分:
- 变量对象(Variable Object) :用于存储变量、函数声明和函数参数。
- 作用域链(Scope Chain) :由当前执行上下文的变量对象和所有父级执行上下文的变量对象组成,用于解析变量和函数的访问。
- this 指向 :根据函数调用方式的不同,确定 this 的指向。
执行阶段:在这个阶段,V8 引擎会将编译阶段中创建的执行上下文压入调用栈。调用栈是一个后进先出(LIFO)的数据结构,用于存储执行上下文。当前正在运行的执行上下文位于调用栈的顶部。接着,V8 引擎会逐行解释执行字节码。在执行过程中,引擎会根据作用域链来解析变量和函数的访问,处理变量赋值、函数调用等操作。当代码执行结束后,V8 引擎会将执行上下文从调用栈中弹出。
模拟语法阶段
例通过 espree JavaScript 解析器 模拟语法阶段
js
import * as espree from 'espree'
// 词法分析
const tokens = espree.tokenize('function a(){}', { ecmaVersion: 6 })
console.log(tokens)
// ast 语法树生成
const ast = espree.parse('function a(){}')
console.log(ast)- 词法分析,它读取字符流(我们的代码)并使用定义的规则将它们组合成标记(token)此外,它将删除空格字符,注释等。最后,整个代码字符串将被拆分为一个标记列表。(一个数组,里面包含很多对象)所谓token,指的是语法上不可能再分的、最小的单个字符或字符串
json
[
Token { type: 'Keyword', value: 'function', start: 0, end: 8 },
Token { type: 'Identifier', value: 'a', start: 9, end: 10 },
Token { type: 'Punctuator', value: '(', start: 10, end: 11 },
Token { type: 'Punctuator', value: ')', start: 11, end: 12 },
Token { type: 'Punctuator', value: '{', start: 12, end: 13 },
Token { type: 'Punctuator', value: '}', start: 13, end: 14 }
]- 语法分析:将在词法分析后获取一个简单的标记列表,并语法分析阶段会把一个令牌流转换成抽象语法树(AST) 的形式。 验证语言语法并抛出语法错误。但如果源码存在语法错误,这一步就会终止,并抛出一个 语法错误
json
{
"type":"Program",
"start":0,
"end":14,
"body":[
{
"type":"FunctionDeclaration",
"start":0,
"end":14,
"id":{
"type":"Identifier",
"start":9,
"end":10,
"name":"a"
},
"params":[
],
"body":{
"type":"BlockStatement",
"start":12,
"end":14,
"body":[
]
},
"expression":false,
"generator":false
}
],
"sourceType":"script"
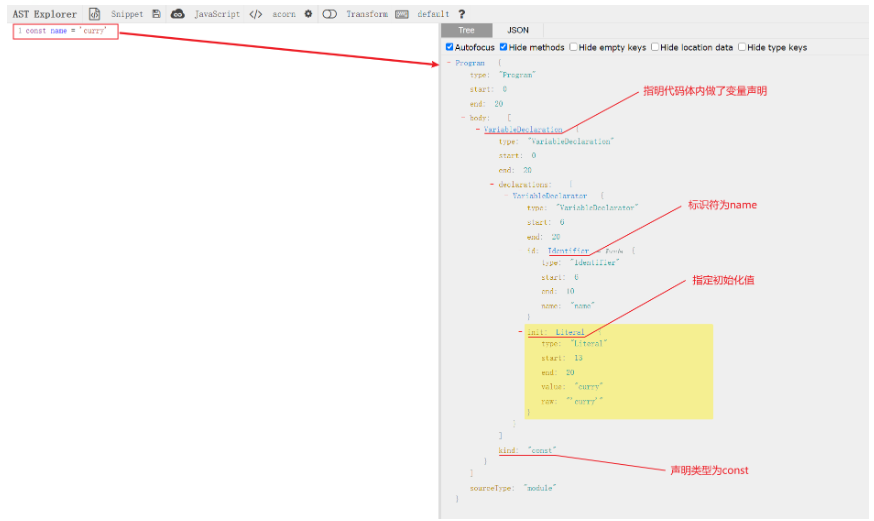
}- 如图 对
const name = 'curry'的ast 语法树 可以使用 AST Explorer 查看